1 运行
(1) 准备
配置HADOOP_CONF_DIR和YARN_CONF_DIR指向Hadoop配置文件目录
用于写入HDFS和连接YARN资源管理器
配置将会在集群荣期间分发
需要确保其中涉及的系统属性在所有节点可用
- 通过spark.yarn.archive或spark.yarn.jars指定运行时库,否则Spark将会在$SPARK_HOME/jars打包所有库并上传至分布式缓存
(2) 运行模式
cluster
驱动程序在应用主进程中运行,客户端只负责应用初始化
client
驱动程序在客户端中运行,主进程只用于请求资源
不同于其他调度框架,YARN总配置文件中获取资源管理器地址,不需显式声明,只需提供– master yarn
1 | // cluster模式 |
(3) 添加库
cluster模式中,驱动程序与客户端不在同一节点,无法使用SparkContext.addJar()。可以在运行参数中使用–jars提交
(4) 配置
2 调试
(1) 容器日志
在YARN中,执行器和Application Master在容器中运行。容器日志有两种处理方式。
1) 聚合后移至HDFS
需要开启yarn.log-aggregation-enable
命令行查看:
使用
yarn logs -applicationId <app ID>访问文件查看:
HDFS中存储路径由
yarn.nodemanager.remote-app-log-dir和yarn.nodemanager.remote-app-log-dir-suffix控制Web UI:
需要同时配置并运行Spark和MapReduce历史服务
配置yarn-site.xml中的yarn.log.server.url
2) 节点本地保存
文件查看:
文件路径在YARN_APP_LOGS_DIR
Web UI:
只需配置并运行Spark历史记录。
(2) 运行环境
用于查看每个容器运行环境,诊断路径问题
增加数据删除延迟 yarn.nodemanager.delete.debug-delay-sec
存储在yarn.nodemanager.local-dirs
包含运行脚本、库、环境变量等
注意:配置需要管理员权限并重启集群
(3) 日志框架
可以使用以下3种方式提交自定义log4j配置:
- 使用spark-submit的–files。驱动和执行器共享相同的配置,注意保持一致。
- 添加
-Dlog4j.configuration=<location of configuration file>到spark.driver.extraJavaOptions(驱动节点)和spark.executor.extraJavaOptions(执行器)。需要显式使用file:协议头。 - 更新$SPARK_CONF_DIR/log4j.properties,运行前自动提交。优先级低于前两者
注意:
容器路径引用可以使用spark.yarn.app.container.log.dir
如log4j.appender.file_appender.File=${spark.yarn.app.container.log.dir}/spark.log
对于流式程序,使用RollingFileAppender和设置文件路径为YARN日志目录将避免磁盘溢出,并且可以通过YARN功能访问日志
自定义metrics.properties可以更新$SPARK_CONF_DIR/metrics.properties,运行前自动提交
(4) YARN相关配置
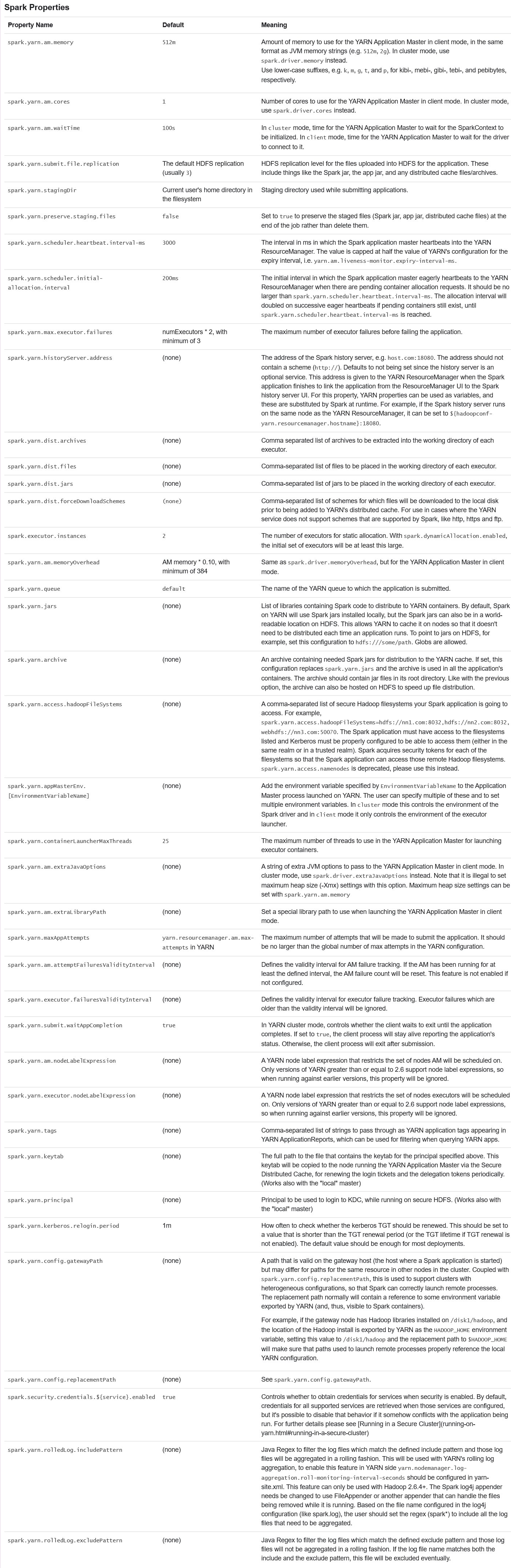
3 注意事项
Whether core requests are honored in scheduling decisions depends on which scheduler is in use and how it is configured.
本地目录
执行器始终使用yarn.nodemanager.local-dirs配置的本地目录
驱动在不同模式,采用不同配置。在cluster模式下使用yarn.nodemanager.local-dirs。但在client模式时,由于驱动不再集群中运行,采用spark.local.dir
--files和--archives支持Hadoop文件别名如localtest.txt#appSees.txt,localtest.txt为上传的实际文件,appSees.txt为程序引用的文件名称
–jars 在集群模式时替代SparkContext.addJar。当对于网络文件路径不必使用。
4 安全
Kerberos用于对服务和客户端应用认证规则。
Hadoop服务需要向获取用于访问服务和数据的token。集群运行时使用token认证。
Spark将为数据存储自动获取令牌。
对于类路径中的HBase,HBase需要声明安全认证框架 (hbase-site.xml中设置hbase.security.authentication为kerberos),并且不要关闭spark.security.credentials.hbase.enabled。
对于类路径中的Hive,需要设置metastore uri(hive.metastore.uris),并且不要关闭spark.security.credentials.hive.enabled
与Spark交互的其他安全Hadoop文件系统需要显式列出,通过spark.yarn.access.hadoopFileSystems列举:
1 | spark.yarn.access.hadoopFileSystems hdfs://ireland.example.org:8020/,webhdfs://frankfurt.example.org:50070/ |
Spark可以通过Java服务机制(详见java.util.ServiceLoader)与其他安全服务集成。
需要在jar包的META-INF/services中列出org.apache.spark.deploy.yarn.security.ServiceCredentialProvider的实现类。
可以设置spark.security.credentials.{service}.enabled为false关闭名为{service}的实现类。
5 配置外部数据交换服务
按照以下步骤在每个NodeManager上启动Spark Shuffle Service:
(1)源码编译时需要启用YARN配置
(2)spark-<version>-yarn-shuffle.jar需要在源码编译的$SPARK_HOME/common/network-yarn/target/scala-<version>或二进制分发包的yarn路径。并且添加到每个NodeManager的类路径中
(3)在yarn-site.xml中添加 spark_shuffle到 yarn.nodemanager.aux-service,设置yarn.nodemanager.aux-services.spark_shuffle.class为org.apache.spark.network.yarn.YarnShuffleService
(4)为了避免垃圾回收问题,在etc/hadoop/yarn-env.sh中设置NodeManager的堆容量YARN_HEAPSIZE(默认1000)
(5)重启NodeManager
6 使用Apache Oozie运行
Apache Oozie可用于将Spark应用作为工作流的一部分。
为了访问集群服务,需要获取响应的令牌。
使用keytab的Spark将自动获取,没有使用的需要将安全设置转交给Oozie。
需要获取令牌的有YARN资源管理器、交互的Hadoop文件系统,用到的Hive、HBase和YARN timeline server.
为了避免Spark获取令牌失败,需要包含以下设置:
1 | spark.security.credentials.hive.enabled false |
7 Kerberos故障排除
开启调试模式并输出额外日志:
1 | # 开启Kerberos的额外日志输出 |
最后,如果org.apache.spark.deploy.yarn.Client的日志等级是DEBUG,将输出令牌和过期时间
8 历史记录服务
为了安全,或减少Spark驱动内存占用,或Web UI不可用时,可以使用历史记录服务作为运行中程序的跟踪URL。
需要进行以下设置:
- 应用程序设置spark.yarn.historyServer.allowTracking=true,以在UI不可用时作为跟踪URL
- 历史记录服务添加org.apache.spark.deploy.yarn.YarnProxyRedirectFilter到spark.ui.filters配置中
注意:历史记录服务可能显示的不是最新的应用状态